Parametric Human Models
Pose Representation
Kinematic Chains
The human poses can be expressed via a kinematic chain, which is a series of local rigid body motions. The rotation of each joint can be represented by a vector
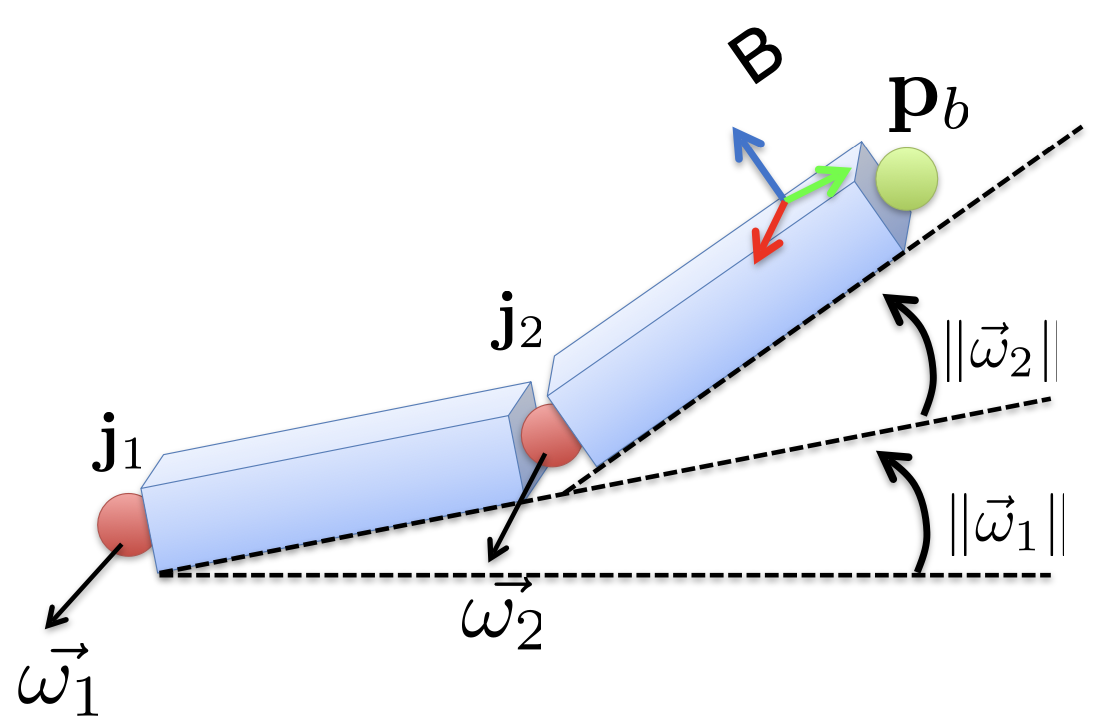
If we want to transform
Pose Parameters
If there are
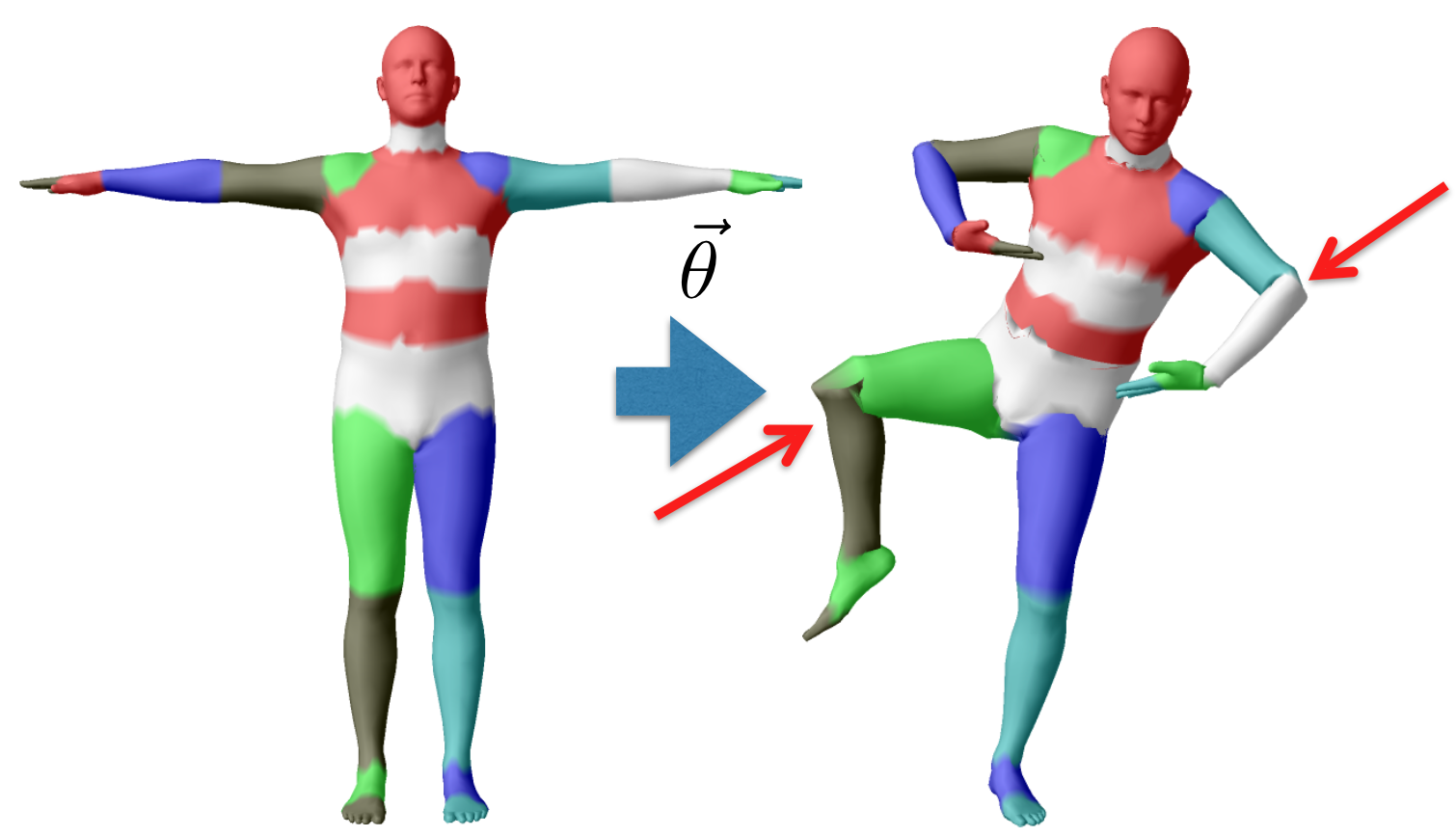
The pose parameters, which are rotations of each joint, can be represented as a vector of concatenated axis-angles:
Problems of Kinematic Chains
Since points on the surface move along with the corresponding bones. If the transformations of two consecutive bones are different, there will be disconnectivity of surface points near joints.
Shape Representation
Linear Blend Skinning
In linear blend skinning (LBS), points are transformed as as blended linear combination of joint transformation matrices. For each vertex
Skinning Functions
Given
- Rest post vertices:
, - Joint locations:
, - Skinning weights:
, - Pose parameters:
,
which can be formulated as
Problems of LBS
There are still artifacts when using LBS, especially when the joint angles are large
or when a bone undergoes a twisting motion. This will result in loss of volume.
Blend Shapes
Blend shapes are offsets added to vertex coordinates. The pose blend shapes, aimed to correct LBS issues, are a function of pose parameters. The shape blend shapes, aimed to introduce shape identity to each character, are fixed under all pose parameters.
The pose blend shape under the pose parameters
The shape blend shapes are obtained by performing PCA on rest pose vertices of different characters. They are chosen to be the eigenvectors corresponding to the largest eigenvalues. Suppose we have
SMPL
Joint Regressor
The joint locations
SMPL
Putting these together, we have the SMPL model:
where
are the input pose, are the input shape, are the rest vertices, are the shape blend shapes, are the pose blend shapes, are the skinning weights, is the joint regressor.
Learning
Model Objective
In the Multishape database, there are about 2,000 single-pose registrations per gender. If we use this to train the model, we want to find the model parameters that minimize a single objective measuring the distance between model and registrations:
where
Registration
In practice, we do not have registrations, which contain fixed number of vertices. We only have scanned point clouds
graph LR
A[Data] --> B[Registration]
B -- " " --> C[Model]
C[Model] -- " " --> BIn the registration step, we aim to find a registration
where
On the other hand, we can optimize the input parameters to the trained model, such that the model also fits the scanned points:
However, we do not learn anything new from the scan. We just find the shape and pose parameters that can fit well.
Ultimately, we can combine these two objective together, to get the final objective
which can be also formulated as follows:
where
Scan-to-mesh Distance
The scan-to-mesh distance is calculated using the following:
where
is a robust function with upper bound.
Coupling
The coupling loss is defined as follows
Priors
The priors are based on Mahalanobis distance if we assume a Gaussian distribution for both
Coregistration
From #Model Objective, we can train a model given registrations, and from #Registration, we can obtain registrations from trained models. To solve both problems at once, the key idea is to minimize the registration objective across the dataset of scans:
In training, the optimization of