Variational Autoencoders
Autoencoders
- An autoencoder consists of an encoder
and a decoder . - The encoder maps the original input from the input space
to the latent space . - The decoder reconstructs the sample from the latent space
to the input space . - Ideally,
.
- A good latent space should represent the data using meaningful degrees of freedom.
- It should have continuity for interpolation (e.g. a vector to control the degree of smile).
Formulation
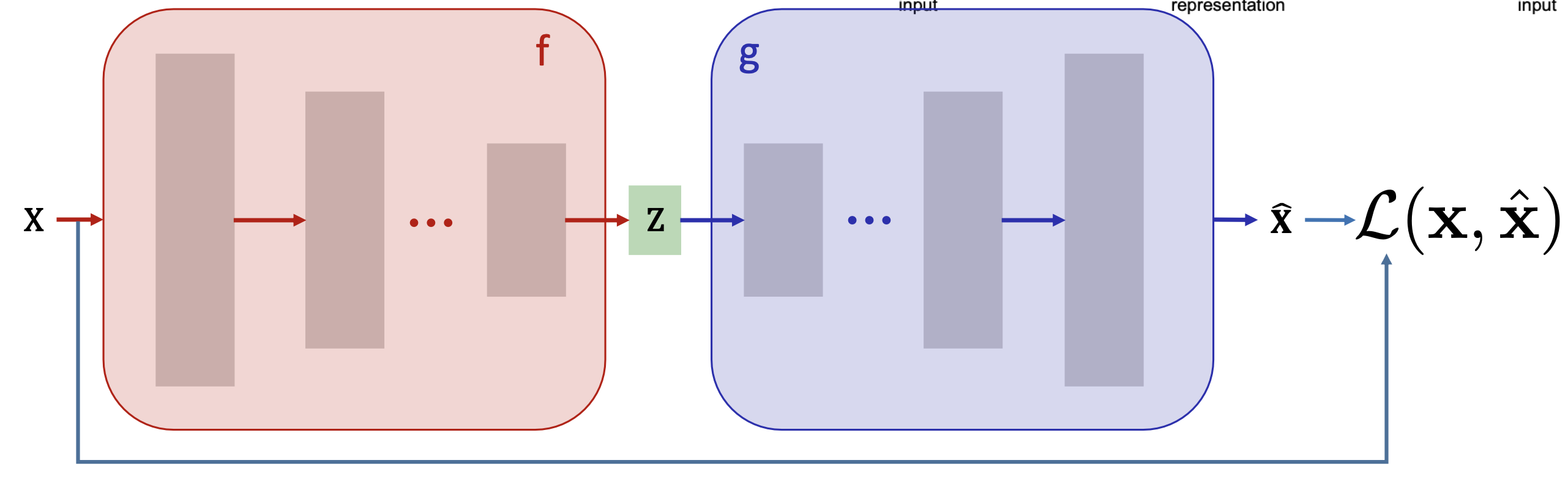
- Given two parameterized mappings
and , training consists of minimizing the reconstruction loss
- In linear cases, PCA is the optimal autoencoder that minimizes the reconstruction loss.
Dimensionality of Hidden Layer
- If
, the hidden layer is called undercomplete. - The hidden layer compresses the input.
- Will compress well for training samples.
- Hidden units will
- Provide good features for training samples.
- Bad for out-of-distribution samples.
- If
, the hidden layer is called overcomplete. - No compression.
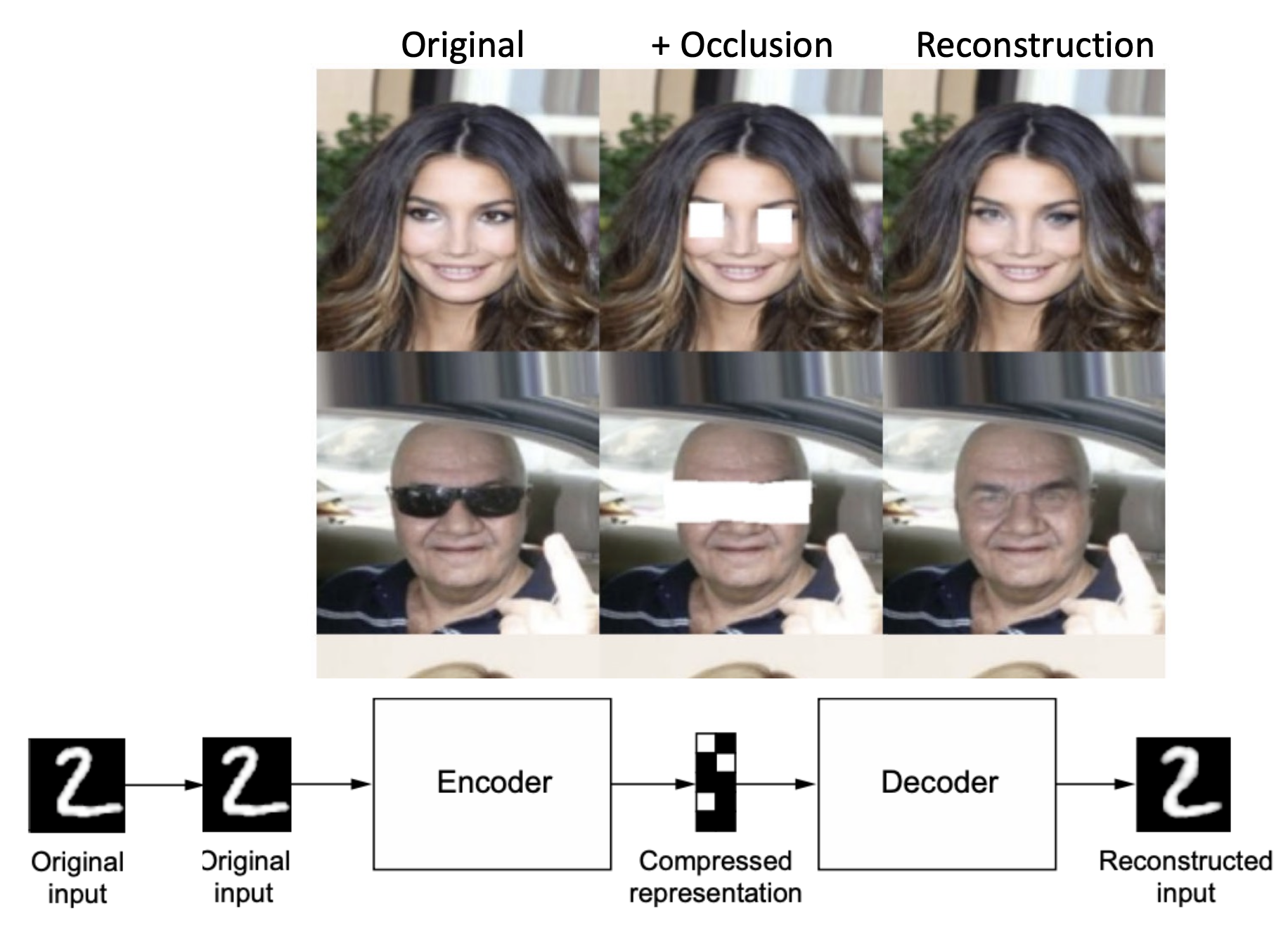
- But should be robust to noise: also called denoising autoencoders.
- Idea for training:
- Add some noise to the input
to get corrupted input . - Reconstruction
computed from . - Loss compares
with origin .
- Add some noise to the input
Limitations of Autoencoders
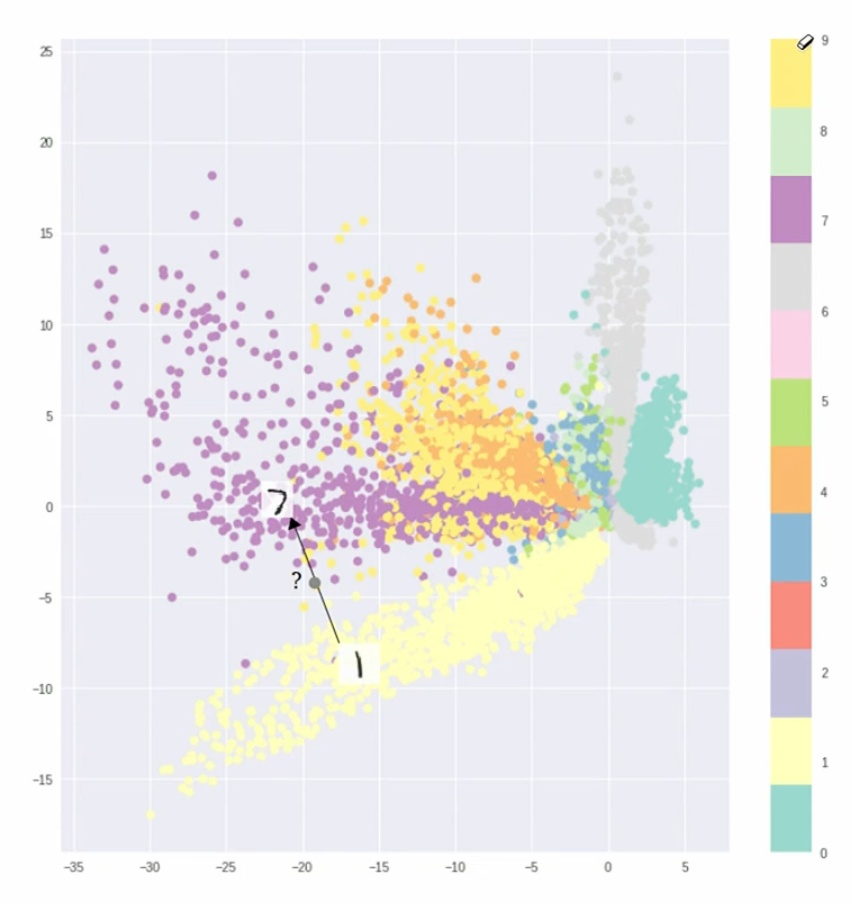
- The decoder is not able to generate good quality samples.
- The latent space is not well-structured: there are some places with no training samples.
Variational Autoencoders (VAE)
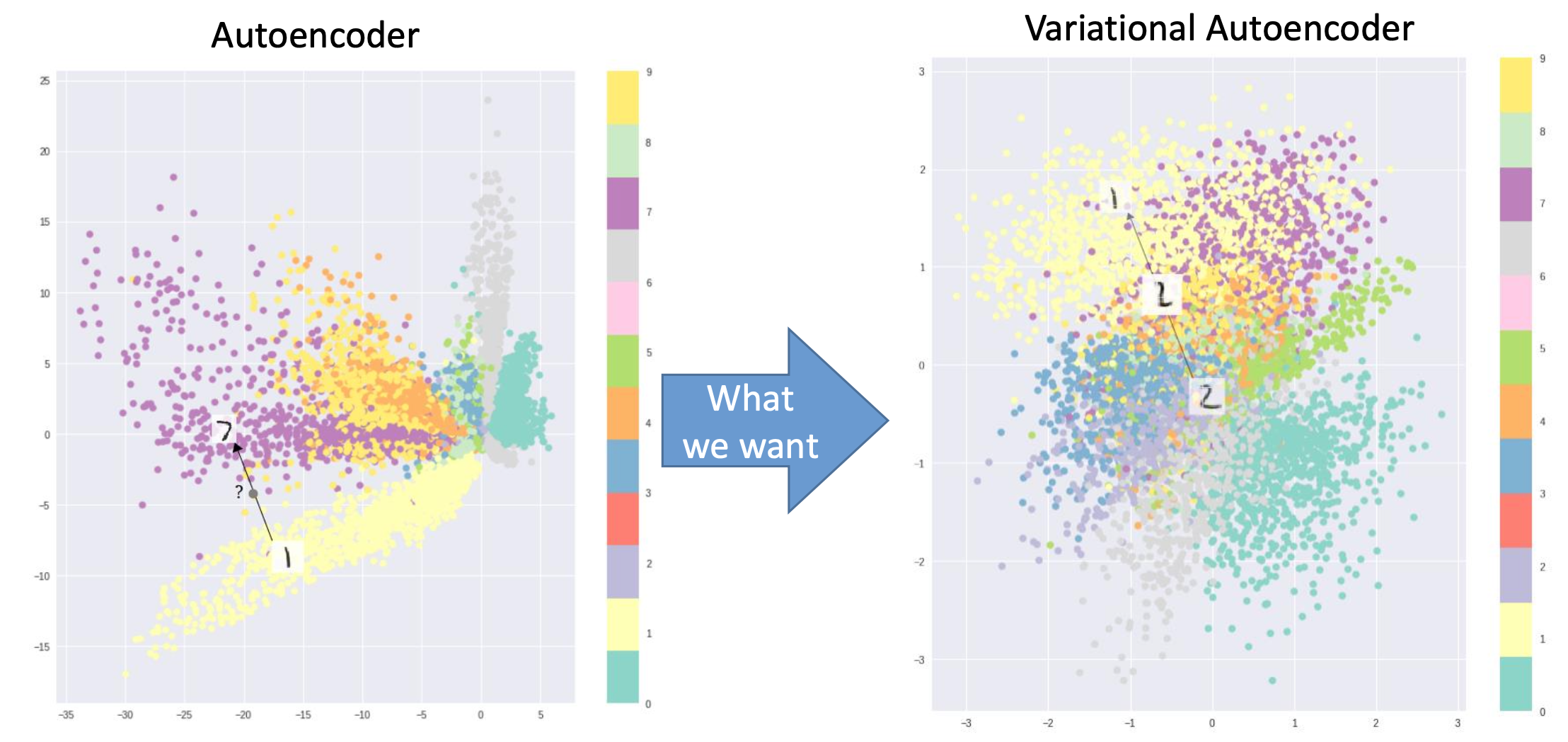
- Instead of predicting a single point in the latent space, we predict a Gaussian distribution
- We can generate new samples from the distribution.
- There is no "holes" in the latent space:
Modeling
- Assume the training data
is generated from underlying latent distribution . - We first sample
from the prior distribution . - Then we sample
from the conditional distribution .
- We first sample
- To best represent prior and conditional:
- We need the prior to be a simple distribution (e.g. Gaussian), so we can sample from it.
- We need the conditional to be complex enough to generate outputs like images: we can represent with DNN.
Training
- In training, we would like to learn model parameters that maximize likelihood of the training data
- However, the integral is intractable because we cannot integral for every
- The posterior density is also intractable
- The solution is to define additional encoder network
to approximate which is tractable (e.g. can be a Gaussian).
Data Log-Likelihood
Since
Using Bayes' rule
- The expectation term is the decoder network.
- The KL divergence term is between Gaussians for encoder and
prior, which has closed-form solution. is called evidence lower bound (ELBO), is the tractable lower bound we can maximize
Forward Pass
- Given the input
, the encoder network gives us a distribution of to sample from
- Given the latent variable
, the decoder network gives us a distribution of to sample from
- In practice, the decoder only predicts the mean value
.
Reparameterization Trick
In order to calculate the gradient regardless of the randomness of sampling. When sampling from the posterior distribution
Given standard normal distribution with
Here the randomness is no longer a function of
VAE Loss
How to calculate this reconstrution loss?
The PDF of multivariate Gaussians is
Therefore, the log-likelihood is
In our decoder, the conditional distribution is
Therefore, maximizing the log-likelihood is equivalent to minimizing the
The VAE loss is derived from the ELBO
- The first term is reconstruction loss:
- Similar samples close to each other.
- The second term is latent code loss:
- Ensure compactness and smooth interpolation.
Generating Data
- Only use decoder.
- Sample
from . - Then sample
from .
Learning Useful Representations
-
Goal: learn features that captures similarities and dissimilarities.
-
Requirement: objective that defines notion of utility.
-
For autoencoders, we usually have entangled representation, which are individual dimensions in latent code encode some unknown combination of features in the data.
-
We would like to learn features that correspond to distinct factors of variation (e.g. digits and style).
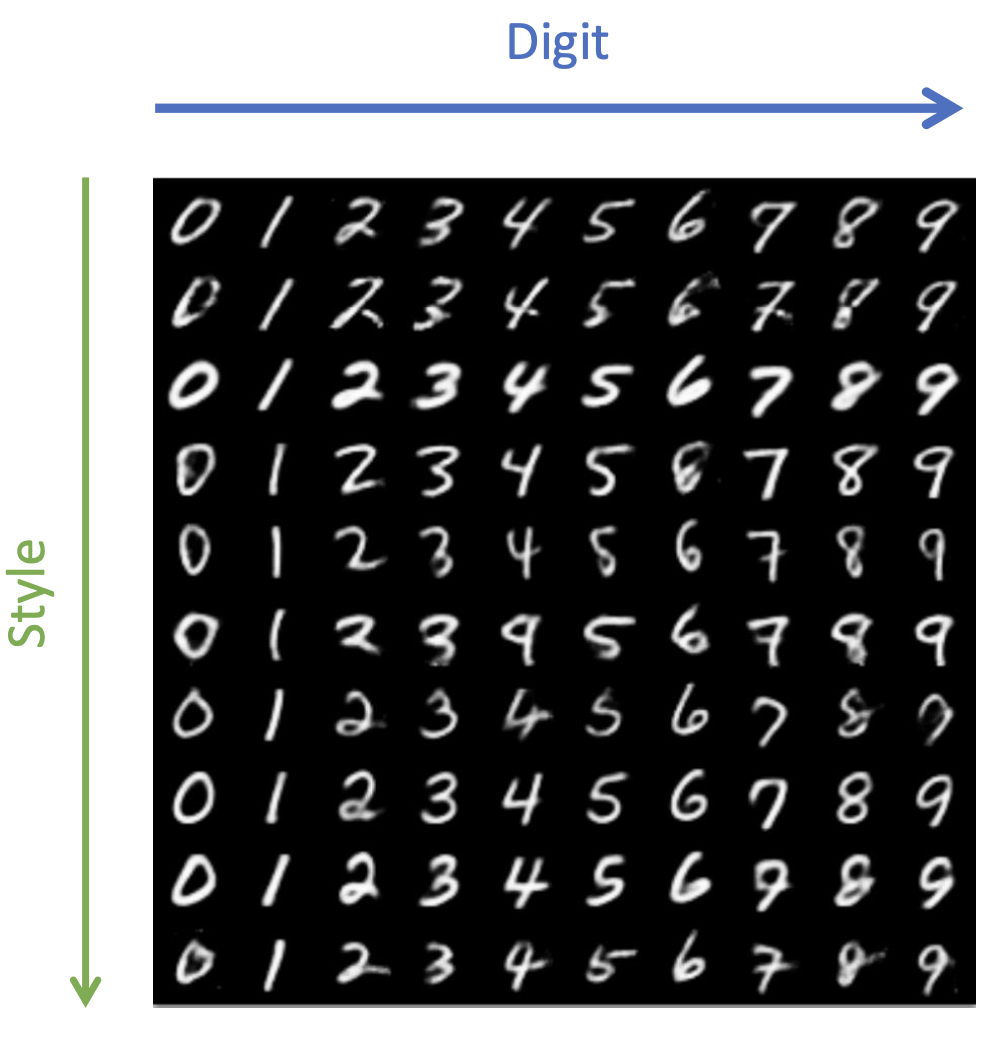
-
Notion of utility: statistical independence can be used.
-
Learning disentangled representation can be achieved with semi-supervised learning.
- For example, we only learn style variable
with digit label : . - Here the style variable is conditionally independent from digit
.
- For example, we only learn style variable
- Goal: learn disentangled representation without supervision.
- Approach: modify the loss if the VAE by introducing an adjustable hyperparameter
that balances latent channel capacity and independence constraints with reconstruction accuracy. - Intuition: the KL loss enforces the distribution to be standard Gaussians, which is independent on each dimension; therefore, increasing the impact of KL loss can make the representation more disentangled.
We can also formulate it. Our goal is to maximize the reconstruction likelihood, while keeping the KL divergence lower than a threshold
Using Lagrange multiplier, we have the objective
Therefore we have the weighted loss
Summary
- Intuition of VAE
- Criteria of a good latent space
- Meaningful degree of freedom (disentangled representations)
- Continuity for interpolation
- Autoencoders map each input to a point in the latent space, making the latent space full of holes and lack of continuity
- Instead, we map the data to a smooth Gaussian distribution
- Criteria of a good latent space
- Theoretical background
- Intractability of VAE
- Optimizing the VAE by maximizing the ELBO: the derivation
- Encoder: Given input
, predict the distribution of the latent variable - Reparameterization: Sampling
given the predicted distribution can be done by the following - Sample from the standard gaussian
- Construct
as
- Sample from the standard gaussian
- Decoder: Given input
, predict the distribution of the input - Loss: the loss consists of reconstruction loss and KL loss
- Reconstruction loss: MSE loss between the input
and the predicted mean of the decoder - KL loss: the KL divergence between
and the prior
- Reconstruction loss: MSE loss between the input
- Generation:
- Sample
from - Use the decoder to sample from
- Sample
-VAE: multiplying the KL loss with a hyperparameter to make the model more disentangled